Triggers
Triggers are responsible for starting job runs automatically. They come in 4 types. The most common are "message filter" triggers, but there are also "cron" triggers, "flow" triggers, and "fail" triggers.
Trigger types
Message Filter Triggers
Message Filter triggers watch for inbound messages and check to see if the data in those messages meet their inclusion criteria and don't meet their exclusion criteria. If they pass these tests and if there are active jobs configured to use that trigger, a run will be started for each message/job combination.
You, the user, specify the inclusion and exclusion criteria which determines
which inbound messages should trigger job runs. Broadly speaking, if part of a
message body matches the JSON you provide as the inclusion filter, and
doesn't match the JSON you provided as the exclusion filter, a job will run
(assuming you created one with autoprocess turned on).
The filter criteria takes the form of a string of valid JSON like this:
{"Name":"Aleksa Iwobi"}. In an SQL query, this string will be used in the
WHERE clause and make use of special jsonb operators like this:
SELECT * FROM messages
WHERE body::jsonb @> '{"Name":"Nicholas Pépé"}'::jsonb;
If you provide a exclusion criteria like {"type": "fake-data"} the resulting
query will look something like this:
SELECT * FROM messages
WHERE body::jsonb @> '{"Name":"Nicholas Pépé"}'::jsonb
AND NOT (body::jsonb @> '{"type":"fake-data"}'::jsonb);
There is a more detailed explanation of filter matching below.
Cron Triggers (formerly timers)
Cron triggers run jobs based on a cron schedule. They can run as frequently as
once every minutes, or as infrequently as you desire and can be scheuled on very
specific dates or times. Each time a timed job succeeds, its final_state will
be saved and used as the initial_state for its next run. See "Managing state"
and "Keeping a cursor" below for implementation help.
The best way to learn about cron, if you're not already familiar, is through
the OpenFn interface or
crontab.guru.
Flow Triggers
Flow triggers will execute a job after another specified job finishes
successfully. E.g., a flow trigger which specifies the succesful run of Job A
can be used by Job B. Each time Job A succeeds, Job B will start to run with the
final_state of Job A as its initial_state.
Fail Triggers
Fail, or "catch", triggers work just like flow triggers, except that they watch for the failure, rather than the success, of a specified job. (E.g., Job A pays a CHW via MPESA. If Job A fails we should initiate Job B, which sends an SMS to the district manager instructing them to manually pay the CHW.)
Processing cron jobs
On-demand processing for cron jobs. If you’re leveraging cron triggers to run jobs at specific times, you can also run that cron triggered job on demand. This way you don’t have to wait for the timer to expire before testing! Simply click the process/ “play” button now available via the Job, Run, and Activity History pages.


Keeping a cursor in state for timer Jobs
Because many timer jobs require keeping some sort of record of their previous
run to modify their later actions, state is passed between the runs. One
example might be keeping a "cursor" to select only new records from a database.
We'd expect the following logic:
job-1fetches patients from the databasejob-1does something important with those patient recordsjob-1saves theidof the last successfully processed patient tofinal_state- when
job-1runs again, it fetches patients whoseidis greater than theidof the last successfully processed patient.
To achieve this you might write:
fetchPatient({ type: 'referral', offset: state.lastId }, state => {
// Assuming the system returned an array of patients in the "data" key.
state.lastId = state.data.patients.sort((a, b) => b.id - a.id)[0];
return state;
});
The initial offset will be null, but the subsequent runs will automatically
only fetch "new" patients.
Managing the size of state for Timer Jobs
Since state is passed between each run of a timer job, if your job adds
something new to state each time it runs, it may quickly become too large to be
practically handled. Imagine if a server response were adding, via
array.push(...), to state.references each time the job ran. OpenFn supports
up to 50,000 bytes (via Erlang's byte_size), though most final_state byte
sizes are between 100 and 1000.
If the size of your final_state exceeds 10,000 bytes, OpenFn will send project
collaborators a warning email. If it exceeds 50,000 bytes, your run will still
succeed but its final_state will not be saved and the next time that job runs
it will inherit the previous, un-updated final state. (I.e., the last state that
was < 50,000 bytes.)
A quick fix for final state bloat
Most often, final state bloat is due to improper handling of state.references
or state.data. This can be fixed by adding the following lines either to the
callback of your language-package's operation (if it allows for one) or by
appending an fn(...) operation after your operation.
fn(state => {
state.custom = somethingIntentional;
state.data = {};
state.references = [];
return state;
});
Filter Matching in Detail
To illustrate filter matching, refer to the filters and message samples below.
- Message "a" will match filter 1, but message "b" will not.
- Message "c" will match filter 2, but message "d" will not.
Filter 1, simple inclusion
The inclusion criteria is { "formID": "patient_registration_v7" } and the
exclusion criteria is left blank.
Message "a" will match
{
"submissionDate": "2016-01-15",
"formID": "patient_registration_v7",
"name": "Jack Wilshere",
"dob": "1986-05-16",
"medications": ["anaphlene", "zaradood", "morphofast"]
}
Message "b" will NOT match
{
"submissionDate": "2016-01-16",
"formID": "patient_registration_v8",
"name": "Larry Bird",
"dob": "1982-03-21",
"medications": ["anaphlene", "zaradood", "morphofast"]
}
Message 'b' does not include "formID":"patient_registration_v7" and will not
match filter '1'.
Filter 2, inclusion and exclusion
The inclusion criteria is { "name": "john doe" } and the exclusion criteria is
{"allowedToShare": false}.
Message "c" will match
{
"submissionDate": "2016-01-15",
"name": "john doe",
"dob": "1986-05-16"
}
Message "d" will NOT match
{
"submissionDate": "2016-01-15",
"name": "john doe",
"dob": "1986-05-16",
"allowedToShare": false
}
More filter samples
Match messages WHERE the formId is "Robot_Photo_21.04.2015"
| inclusion | exclusion |
|---|---|
{ "formId": "Robot_Photo_21.04.2015" } |
Match a message with two fragments inside an array called data
(This is useful when gathering data via ODK)
| inclusion | exclusion |
|---|---|
{ "data": [{ "outlet_call": "TRUE", "new_existing": "Existing" }] } |
Match a message WHERE this AND that are both included
| inclusion | exclusion |
|---|---|
{ "formId": "Robot_Photo_21.04.2015", "secret_number": 8 } |
Match a message using exclusion
| inclusion | exclusion |
|---|---|
{ "formId": "Robot_Photo_21.04.2015" } | { "safeToProcess": false } |
Match a message with a fragment inside another object called form
| inclusion | exclusion |
|---|---|
{"form": {"@xmlns": "http://openrosa.org/formdesigner/F732194-3278-nota-ReAL-one"}} |
An exclusion demo
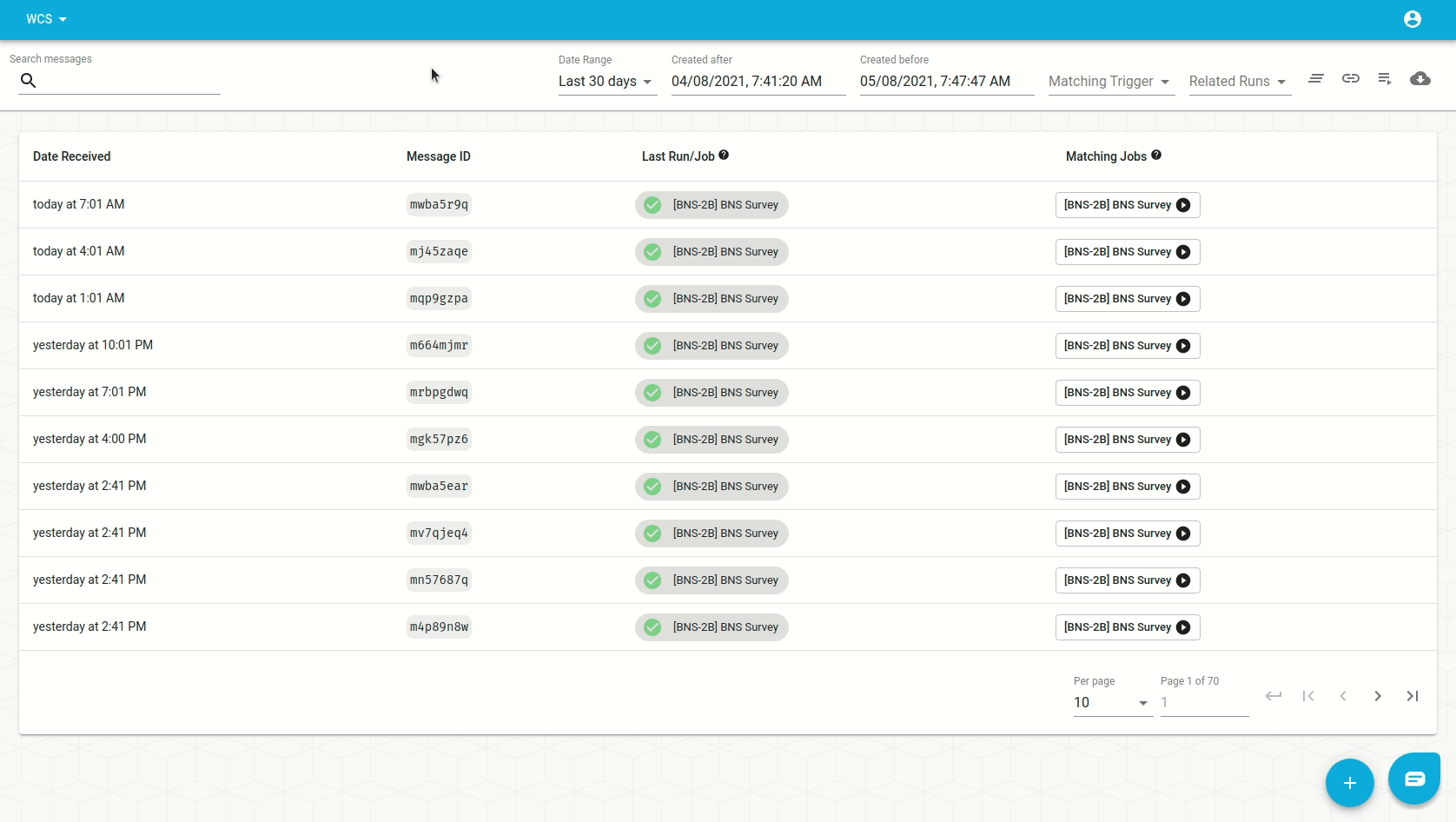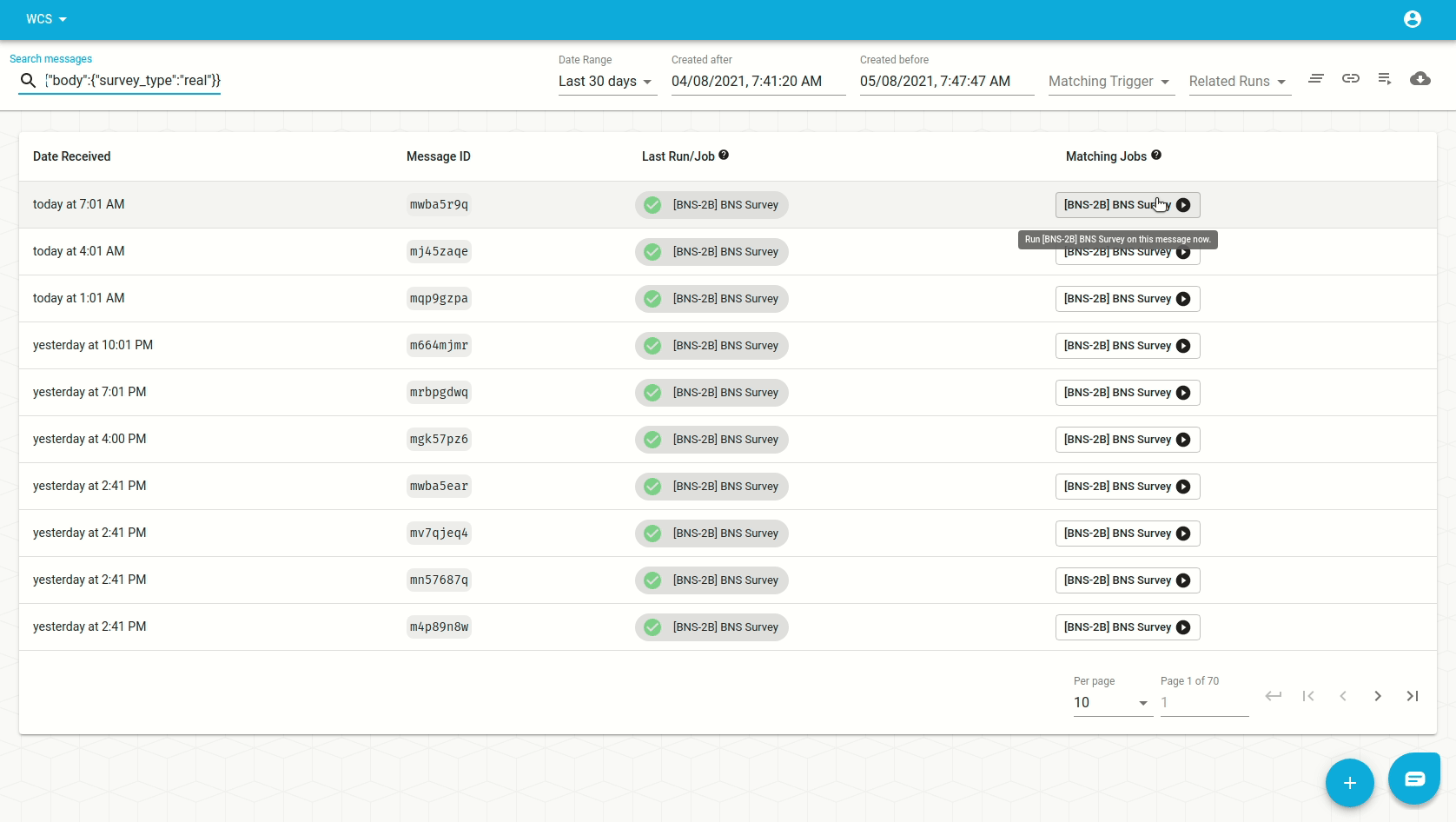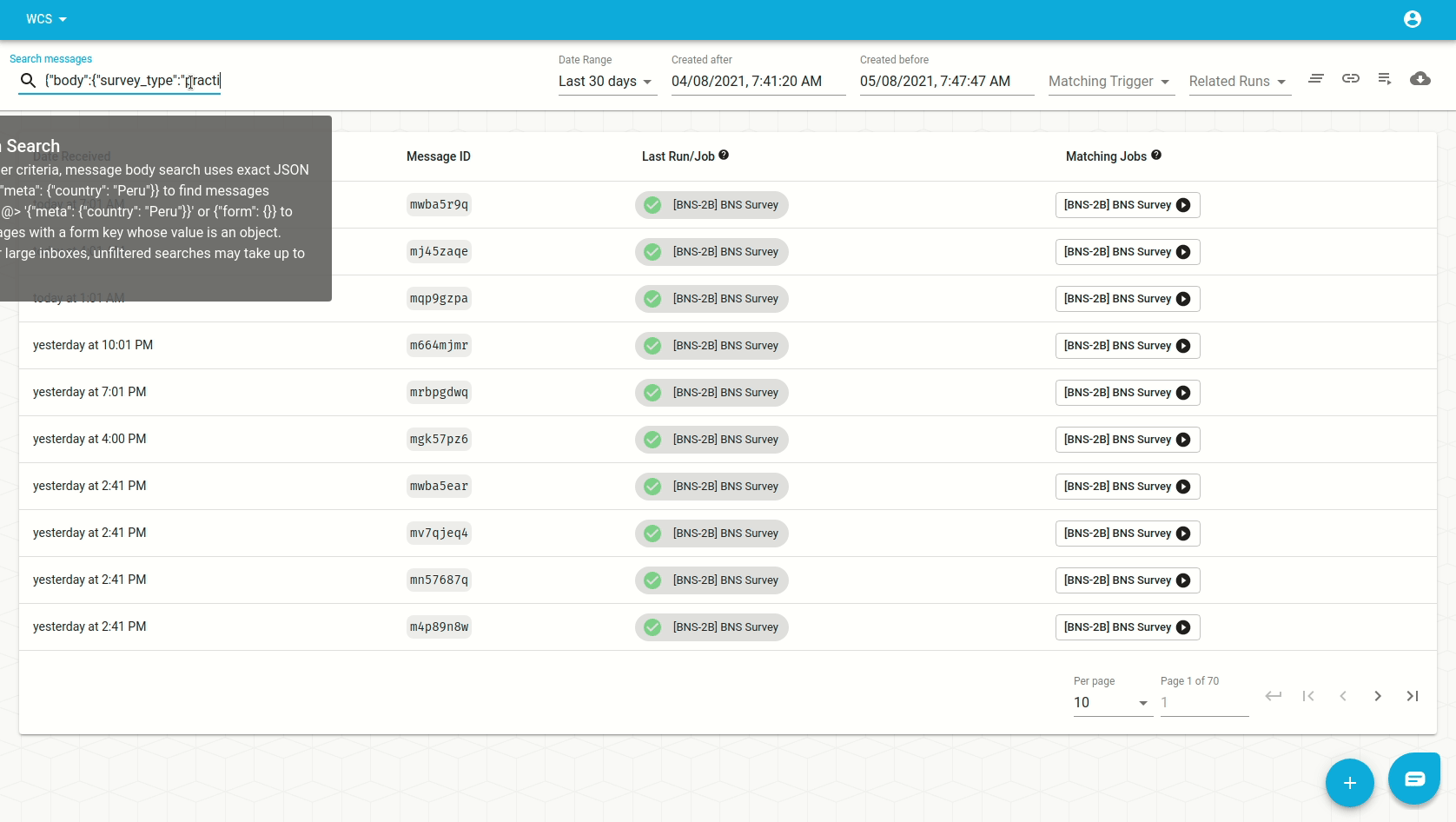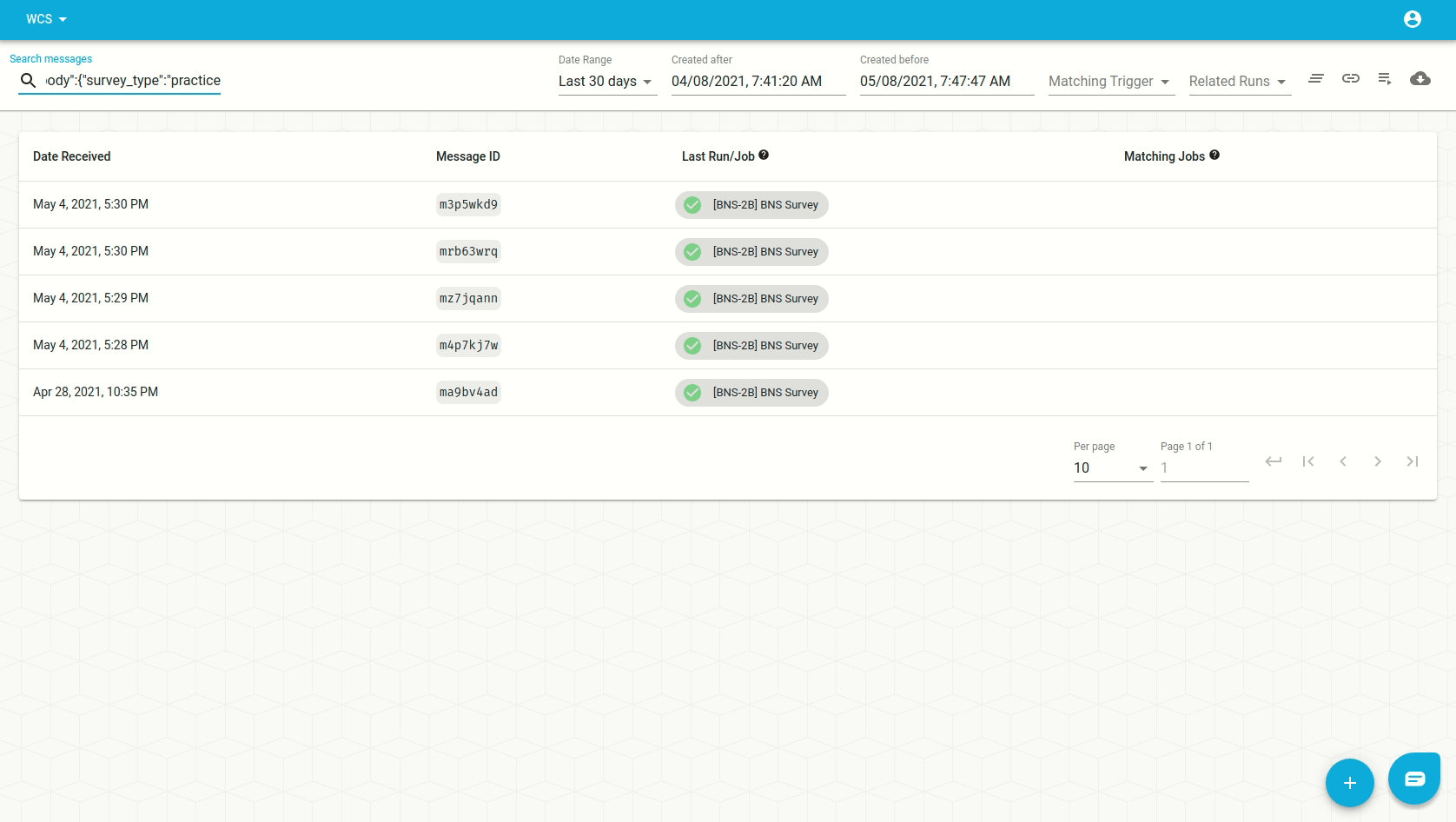
Imagine that we had a filter which included messages with form == 'bns_survey'
but we then want to start excluding those that have
body.survey_type == 'practice'. Our filter trigger would look need to like
this:
| inclusion | exclusion |
|---|---|
{ "form": "bns_survey" } | {"body": {"survey_type": "practice"}} |
We'd set it up from the trigger form like this:
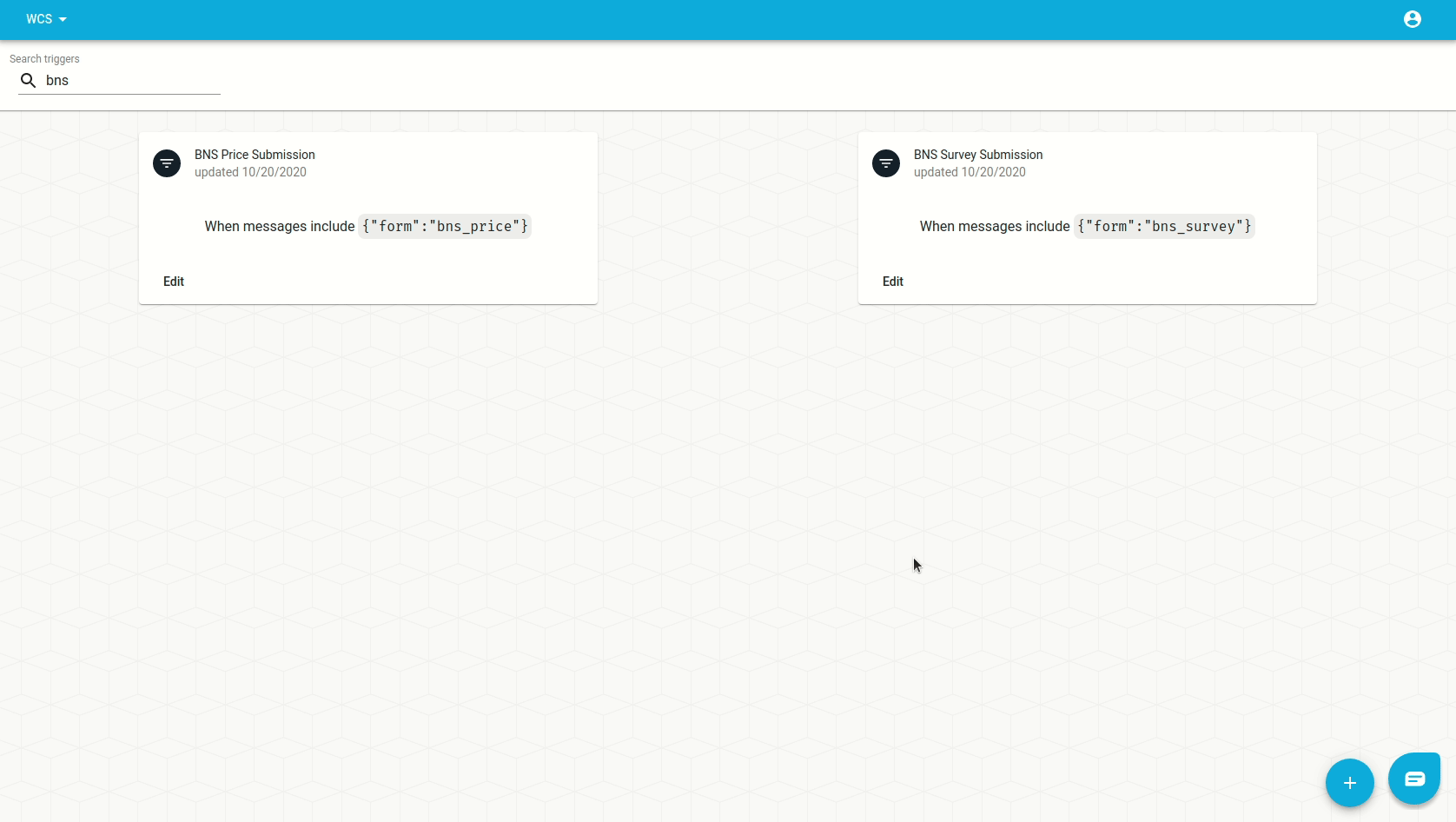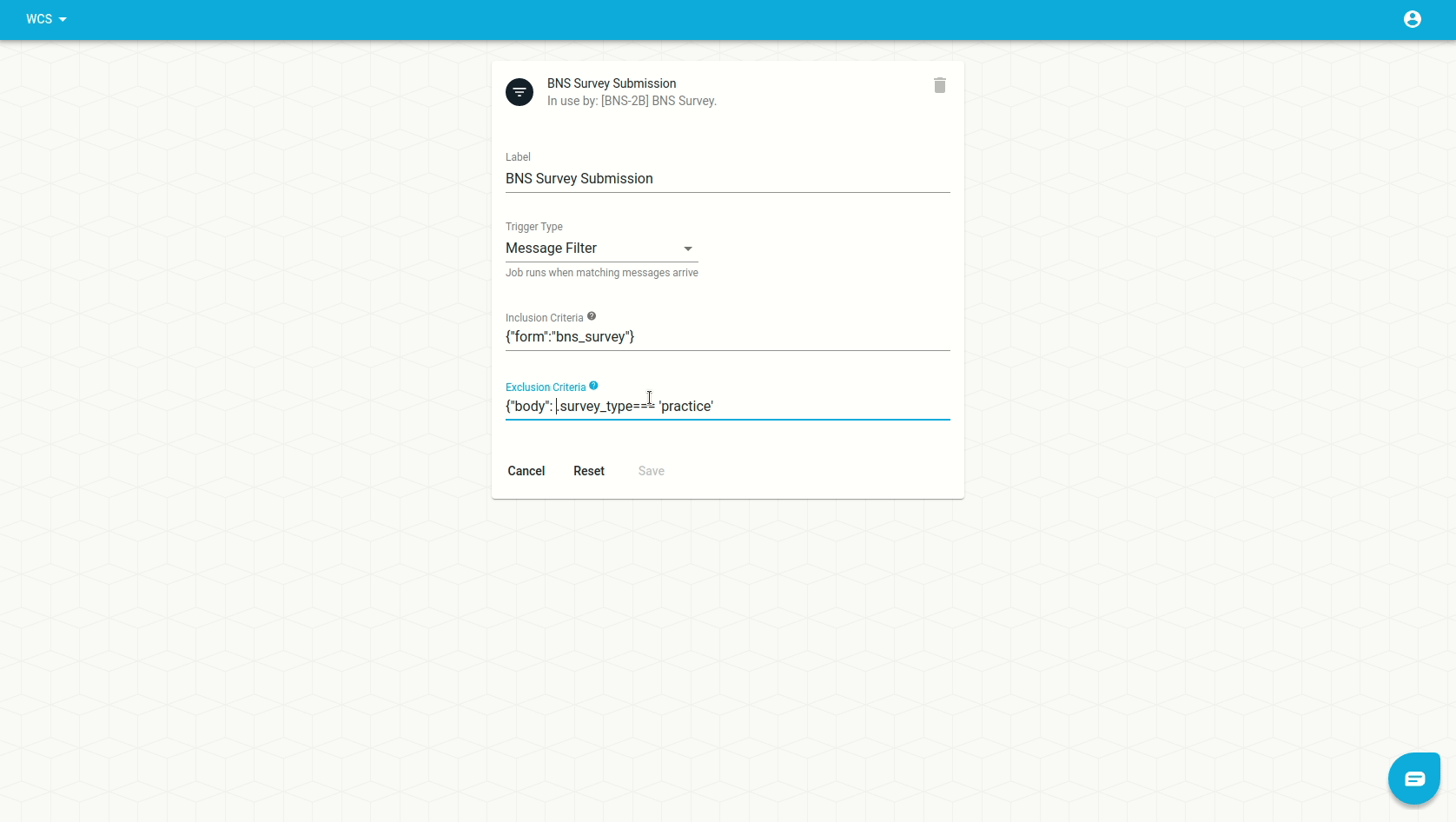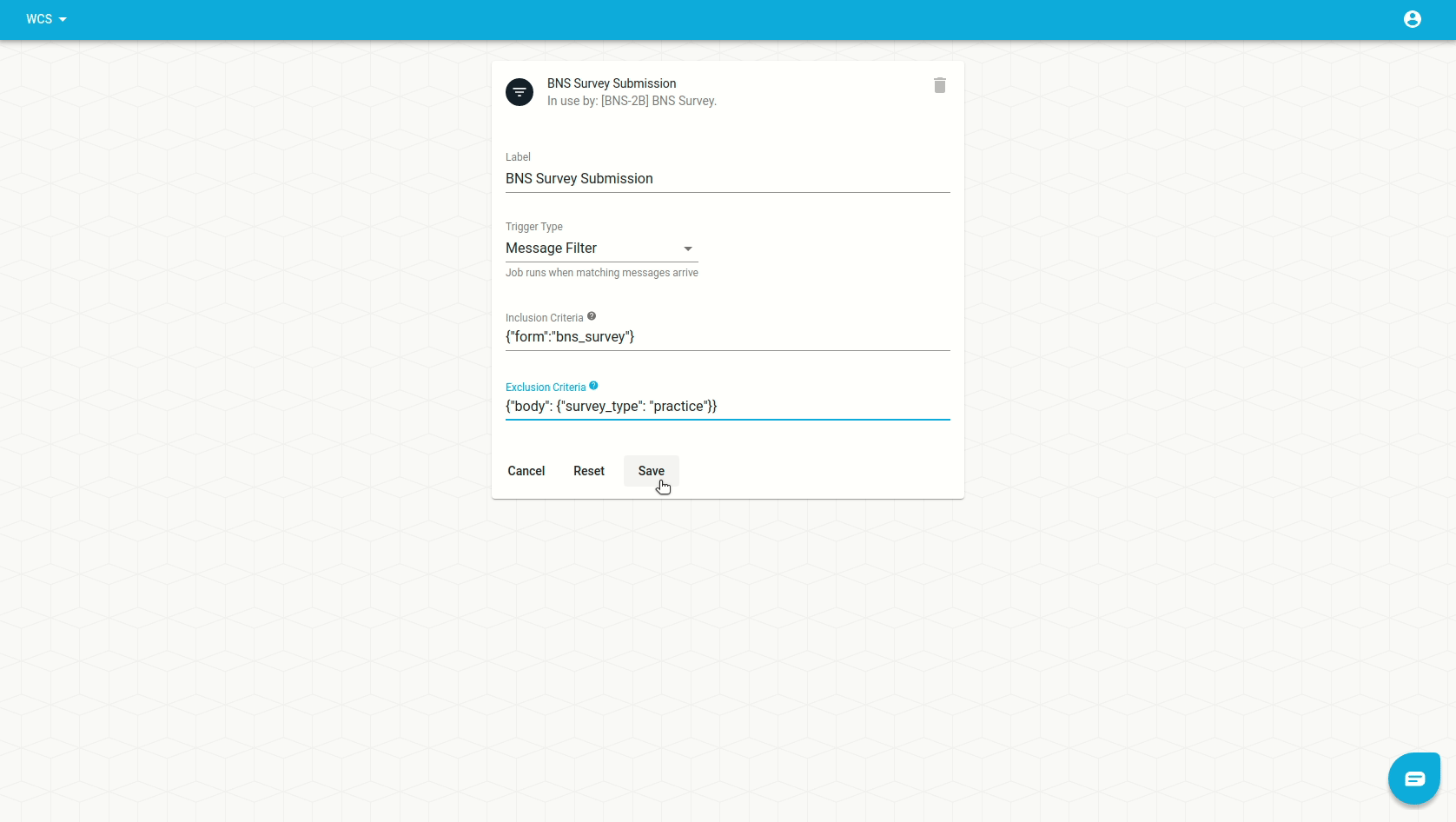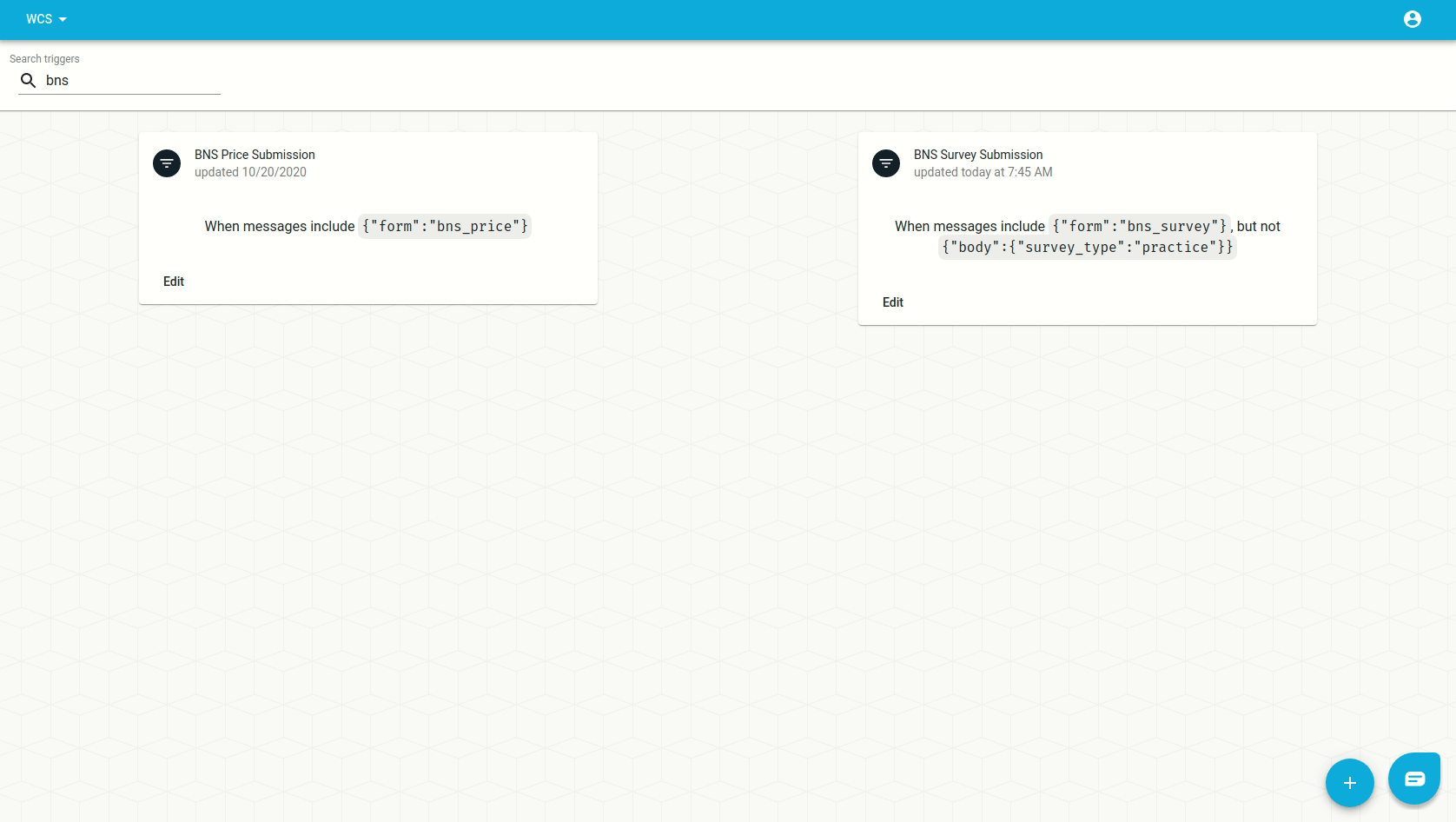
And verify the result on the inbox: