Triggers
Triggers allow you to start the execution of Workflows automatically. They come in three types: Cron triggers, Webhook Event, and Kafka triggers.
Webhook Event Triggers
Webhook Event Triggers listen for inbound HTTP requests (messages from other systems), and enable real-time, event-based automation.
These triggers are fired by "pushing" data to OpenFn (i.e., by sending an HTTP “POST” request to your trigger’s designated URL).
The triggering HTTP request might be sent via a webhook in an external app, another OpenFn workflow, or manually (i.e., via cURL request).

To learn about how to add an additional layer of security to your Webhook Trigger by adding authentication, head over to our Webhook Security page.
Learn how a workflow's initial state gets built from a webhook trigger
here.
Webhook Trigger Responses
When a workflow is triggered via a webhook, OpenFn can respond to the calling system in one of two ways, depending on how the trigger is configured.
Async Mode Responds Before Start
By default, workflows are executed asynchronously.
OpenFn sends an HTTP response immediately after receiving the webhook request, once the Work Order and Run have been created. The calling system gets a fast acknowledgement and the workflow runs in the background.
Use this mode when:
- The calling system only needs confirmation that the request was received
- You want fast responses and minimal coupling
- The calling system does not need the result of the workflow run
Response:
- Status code:
200 - Headers:
x-meta-work-order-id— the ID of the created work orderx-meta-run-id— the ID of the created run
- Body:
{"work_order_id": "abc123","run_id": "xyz456"}
Sync Mode Responds After Completion
Optionally, workflows can be executed synchronously.
OpenFn holds the HTTP connection open and sends a response after the run finishes, returning the final run state as the response body. The calling system waits — sometimes seconds or minutes — for the result.
Use this mode when:
- The calling system needs the result of the workflow run
- You need the workflow’s final output to drive the next step in the caller
Default response:
- Status code:
201(configurable — see below) - Headers:
x-meta-work-order-id— the ID of the work orderx-meta-run-id— the ID of the run
- Body: a JSON object with the shape:
{"data": { /* the final run state */ },"meta": {"work_order_id": "abc123","run_id": "xyz456","state": "success","error_type": null,"inserted_at": "2026-05-21T10:00:00Z","started_at": "2026-05-21T10:00:01Z","claimed_at": "2026-05-21T10:00:01Z","finished_at": "2026-05-21T10:00:05Z"}}
data— the final run state (or a security message on failure, or a custom body — see below)meta— run metadata, including run lifecycle timestamps and finalstate("success"or"failed")
When a run fails, OpenFn returns a generic message in data rather than the
full run state, to avoid leaking sensitive data. You can still return a custom
body from a failed run using webhookResponse (see below).
Configuring custom status codes
In sync mode you can set custom HTTP status codes on the trigger (under Options → Response Status in the UI):
- Success Status Code — returned when the run completes successfully
(defaults to
201) - Error Status Code — returned when the run fails (defaults to
201)
Switching a trigger back to async mode clears any configured success or error status codes, they only apply in sync mode.
Customising the response from your job
To return a custom body or status code from values at runtime, set webhookResponse in the state, e.g.:
fn(state => ({
...state,
webhookResponse: {
status: 200,
body: { ack: true, id: state.data.id },
},
}));
At the end of the run, the value of state.webhookResponse will be used to
send the HTTP response back to the caller. Changing the value during the run
does not affect the response, it's only the final state that counts.
Both status and body are optional — you can include either or both:
| Field | Behaviour when set |
|---|---|
status | Overrides the configured status code for this run |
body | Replaces the final run state under data in the response body |
| neither | Falls back to the configured status code and final run state |
webhookResponse.body only replaces the data portion of the response —
meta is always included by OpenFn. So the example above produces:
{
"data": { "ack": true, "id": "..." },
"meta": { "work_order_id": "...", "run_id": "...", "state": "success", ... }
}
If webhookResponse is not a JSON object (e.g. a string, number, or array), it
is ignored and the run's default status code and body apply.
If webhookResponse.status is not an integer, or webhookResponse.body is not
a JSON object, the response status falls back to the run's default (the
configured success or error code, or 201) and data is replaced with
{ "message": "Run completed, but webhook_response was malformed: ..." }.
Cron Triggers
Cron Triggers run Workflows based on a cron schedule, and are good for repetitive tasks that are time-based (e.g., every day at 8am, sync financial data between two systems).
These Triggers enable users to "pull" data from connected systems. You can pick a standard schedule (e.g., every day, or every month), or define a custom schedule using cron expressions.
The best way to learn about cron, if you're not already familiar, is through
the OpenFn interface or
crontab.guru.
Cron Triggers enable Workflows to be run as frequently as once every minute, or as infrequently as you desire and can be scheduled on very specific dates or times.
Input state for the next run
Every time a cron-triggered workflow is run it will start with the final output of the last successful run. This allows users to build workflows that make use of a "cursor" that tracks what happened last time the workflow ran. (Only processing data that changed since that last run, for example.)
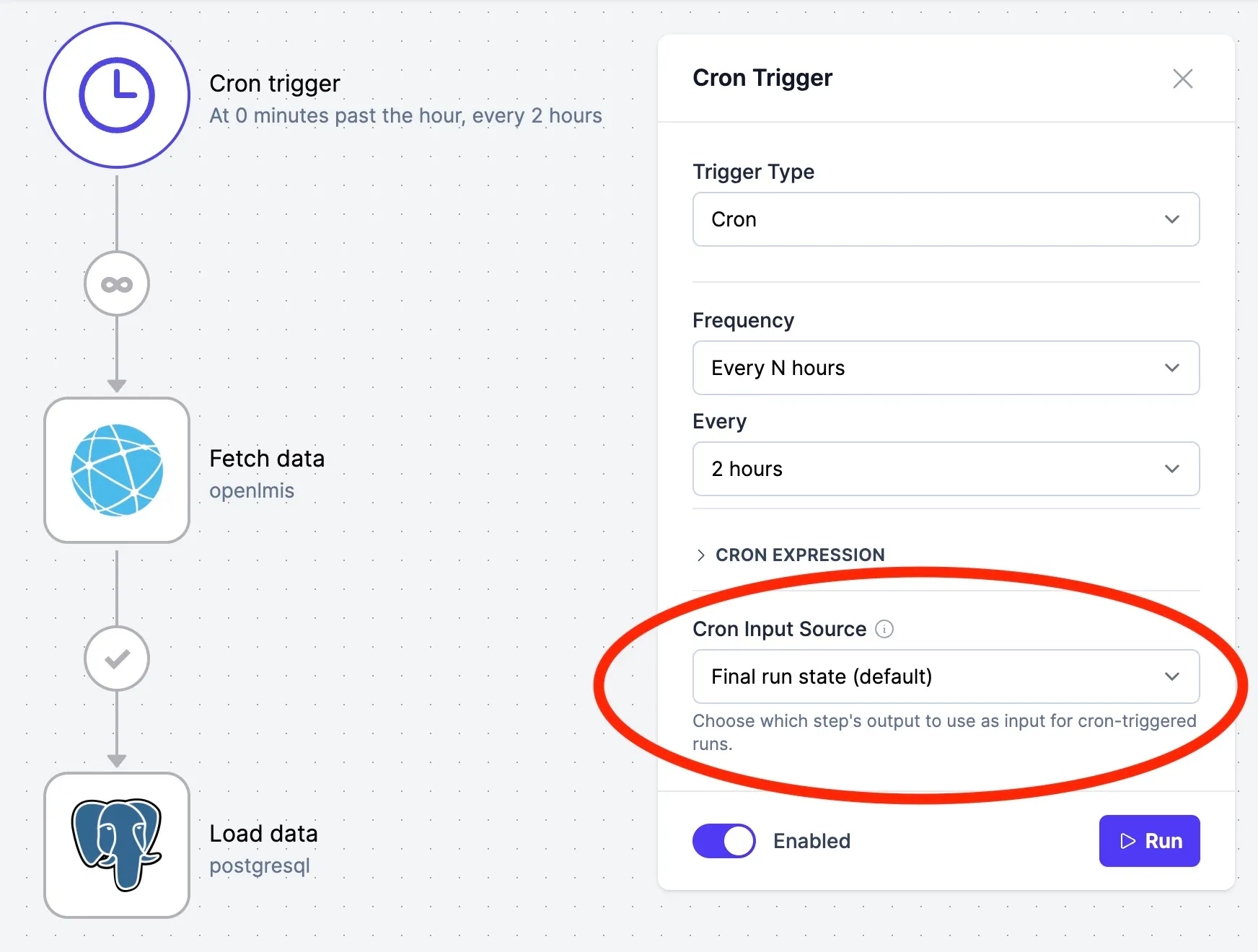
Be default, the input state for the next cron run will be the final output state of the previous run, but you can configure this to use the output state from a specific step in your earlier run by changing the "Cron Input Source".
More on state in cron-triggered runs can be found in the
"Input and Output State" docs.
Managing the size of state for Cron Workflows
Since state is passed between each run of a cron Workflow, if your Workflow Step
adds something new to state each time it runs, it may quickly become too large
to be practically handled. Imagine if a server response were adding, via
array.push(...), to state.references each time the job ran. OpenFn supports
up to 50,000 bytes (via Erlang's byte_size), though most final_state byte
sizes are between 100 and 1000.
If the size of your final_state exceeds 10,000 bytes, OpenFn will send project
collaborators a warning email. If it exceeds 50,000 bytes, your run will still
succeed but its final_state will not be saved and the next time that job runs
it will inherit the previous, un-updated final state. (I.e., the last state that
was < 50,000 bytes.)
A quick fix for final state bloat
Most often, final state bloat is due to improper handling of
state.references or state.data. This can be fixed by cleaning up your final
state by adding and customizing the following lines either to the callback
of your language-package's operation (if it allows for one) or by appending a
fn(...) operation after your final operation.
fn(state => {
state.custom = somethingIntentional;
state.data = {};
state.references = [];
return state;
});
Kafka Triggers (beta) 🚧
The Kafka trigger allows OpenFn users to build Workflows triggered by messages
published by a Kafka cluster. The triggers make use of Kafka consumer groups
that are set up on-demand to receive messages from a defined cluster then
converts them to Input dataclips that are used to initialize a Work Order.
Instance administrators have to enable Kafka for their instance by setting
KAFKA_TRIGGERS_ENABLED=yes in the environment variable.
Apache Kafka® is an event streaming platform designed to handle high volumes of data. Check out Kafka Docs to learn more.
Configuring a Kafka trigger for your workflow
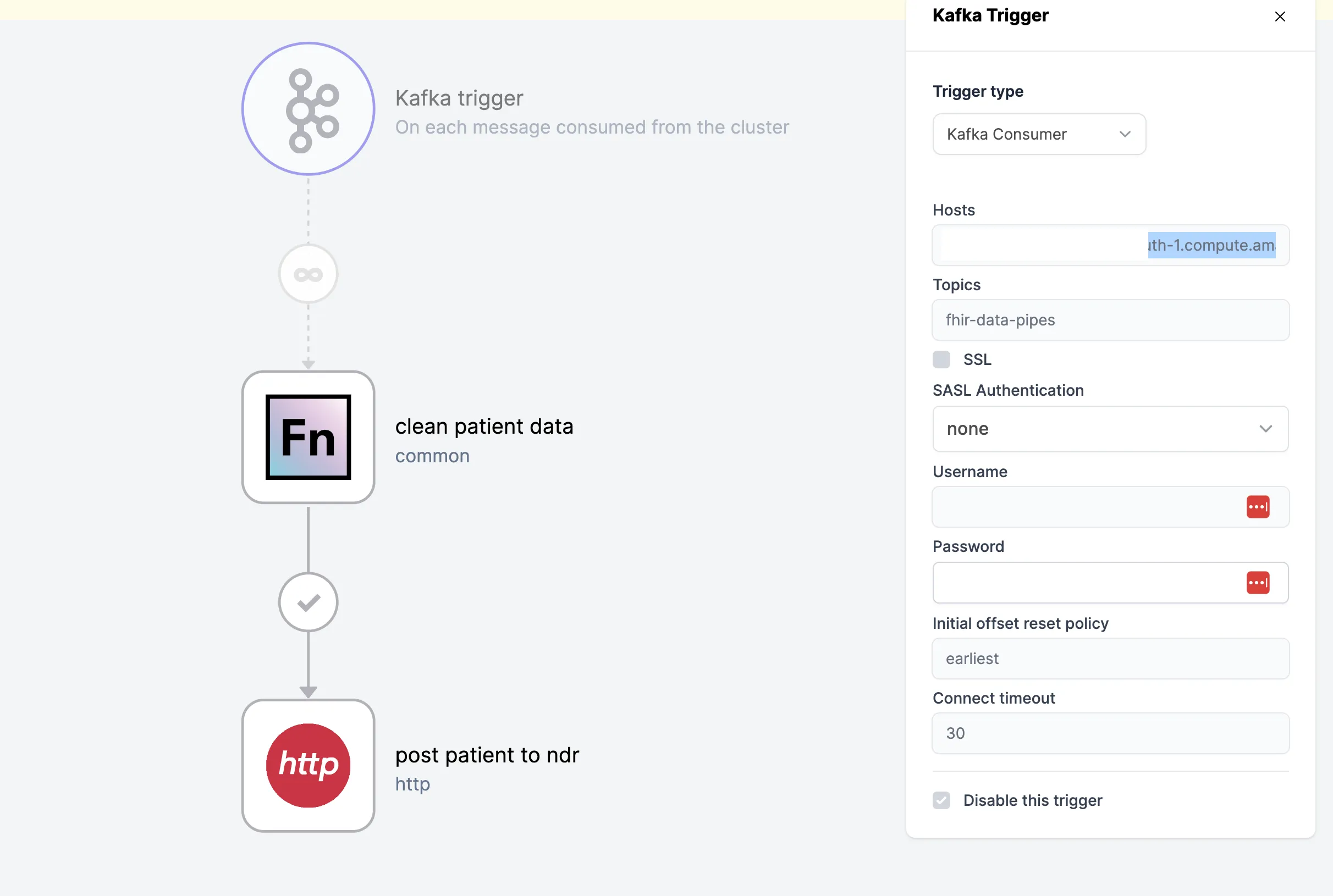
- Create a new Workflow or open an existing Workflow in your Project
- Click on the workflow's Trigger and change the trigger type to
Kafka Consumerin theTrigger typedropdown. - Fill out the required connection details:
- Hosts: Provide the URL of the host(s) your trigger should listen to for messages.
- Topics: Enter the topics your Kafka consumers should subscribe to. You need at least one topic for a successful connection.
- SSL: Some Kafka clusters require SSL connection. If you are connecting to
an environment that requires SSL connection, select
Enable SSL. - SSL Authentication: Select the type of Authentication required for the Kafka cluster.
- Initial offset policy: The intial offset dictates where the consumer
starts reading messages from a topic when it subscribes for the first time.
There are three possible options:
earliestmessages available,latestmessages available, or messages with a specifictimestamp(e.g.,1721889238000). - Connect timeout: The connect timeout specified in seconds (e.g.,
30) represents how long the consumer should wait before timing out when attempting to connect with a Kafka cluster.
- If you have not finished designing your Workflow or you're not ready to start receiving messages from the Kafka cluster, please check the box to disable the trigger until you're ready for message ingestion to begin.
Once the required connection information is provided via the modal, the trigger
will immediately start attempting to connect to the Kafka cluster. We advise
that the trigger is disabled until your workflow is ready to receive data from
the cluster for processing. To stop the trigger from receiving and processing
messages, check the Disable this trigger checkbox at the bottom of the trigger
configuration modal.
Learn how the initial state (and Input) for Kafka-triggered Workflows gets
built here.
Known "sharp edges" on the Kafka trigger feature
We'll monitor bug/exception reports, perform user interviews and collect feature requests during the beta to determine which of these rough-edges are worth ironing out, and how to do so assuming that the community wants to support Kafka triggers going forward. Please don't hesitate to reach out on community.openfn.org to make your voice heard!
- Performance settings are out of the end-user's control and can only be set at instance-level. As there is quite a close relationship between cluster and consumer settings, this may prove to be an obstacle as users will not be able to tune their consumers to align with their individual clusters in large multi-tenant deployments.
- If a message could not be turned into a work order (due to persistence errors or hitting the hard limit), these will not be visible to the end-user and may be lost forever (i.e. the cluster thinks Lightning has them but it doesn't and they eventually rotate off the cluster)
- Errors are written to the log and to Sentry; nothing is visible to the end-user.
- Reprocessing dropped messages isn't practical if you are not writing failed messages to some sort of persistent file storage.
- If a consumer group is disconnected from a cluster long enough for the cluster to forget the last message, we may not be able to prevent duplicates making it through (as a result of instance-wide de-duplication settings).
- We cannot provide concurrency and honour message sequence that is based on the Kafka message key mechanism. If a user wants to guarantee the Kafka message sequence, they must enable 1-at-a-time processing on OpenFn by turning their workflow concurrency down to 1.