Input and output state
Each Job requires an input state and (in most cases) will produce an output state. This article explains these concepts in greater detail.
Every job is a data transformation pipeline. It takes some input (a JavaScript object we call State) and executes a set of Operations (or functions), which transform that state in series. The final state object is returned as the output of the pipeline.

The final state from a Job must always be a serializable JavaScript object (i.e., a JSON object). Any non-serializable keys will be removed.

Input state is often referred to as initial state, and output state is often referred as final state. These terms can safely be used interchangeably.
State Keys
State objects tend to have the following keys:
data: a temporary information store, usually used to save the result of particular operationconfiguration: an object containing credential datareferences: a history of previousdatavaluesresponse: often used by adaptors (like http) to save the raw http response from a requesterrors: a list of errors generated by a particular Workflow, indexed by Job name.
At the end of a Job, the configuration key will be removed, along with any other non serializable keys.
Adaptors will occasionally write extra information to state during a run - for
example, database Adaptors tend to write a client key to state, used to track
the database connection. These will be removed at the end of a Job.
Input & output state for runs
Depending on whether you're running Workflows locally via the CLI or on the app, the input state for a Run must be generated differently:
- When manually creating a work order, you must select or generate your input
manually (e.g., by creating a custom
Inputon the app orstate.jsonfile if working locally in the CLI). - When a work order is automatically created via a webhook trigger or cron trigger, state will be created as described below.
The final state of a Run is determined by what's returned from the last operation. Remember that job expressions are a series of operations: they each take state and return state, after creating any number of side effects. The final returned state controls what is output by the run at the end of all of these operations.
Best practice is to include a final state cleanup step that removes any data that should not persist between runs or be output (like PII), for example:
// get data from a data source
get('https://jsonplaceholder.typicode.com/users');
// store retrieved data in state for use later in job
fn(state => {
state.users = state.data;
return state;
});
// get more data from another data source
get('https://jsonplaceholder.typicode.com/posts');
// store additional retrieved data in state for use later in job
fn(state => {
state.posts = state.data;
return state;
});
// compare data
fn(state => {
if (state.users.length > state.posts.length) {
// do something based on the comparison
}
return state;
});
// cleanup state at the end before finishing job
fn(state => {
state.data = null;
state.users = null;
state.posts = null;
return state;
});
There are a few common patterns for cleaning up final state. You can return only the keys you need:
fn(state => {
return {
data: state.data,
};
});
Use the spread operator to keep everything but override specific keys:
fn(state => {
return {
...state,
secretStuff: null,
};
});
Or use the rest operator to exclude specific keys entirely:
fn(state => {
const { username, password, secrets, ...rest } = state;
return rest;
});
Webhook triggered runs
On the platform, when a Run is triggered by a webhook event, the input state contains important parts of the inbound http request.
The input state will look something like this:
{
data: { // the body of the http request
formId: "patient_enrollment",
name: "John Doe"
},
request: {
method: "POST",
path: ['i', 'your-webhook-url-uuid'] // an ordered array with optional additional paths
headers: { "content-type": "application/json" }, // an object containing the headers of the request
query_params: {} // an object containig any query parameters
},
}
Kafka triggered runs
When a Kafka message is fetched by the trigger, the input state contains the message body and information that can be used for auditing or recovery if connections are lost or workorders fail.
The input state looks like this:
{
data: { // the message value
formId: "patient_enrollment",
name: "John Doe"
},
request: {
"headers": [
// kafka headers can be used to provide additional metadata
],
"key": "", // the key assigned to the message by the publisher
"offset": 168321,
"partition": 1,
"topic": "fhir-data-pipes",
"ts": 1721889238000 // the kafka message timestamp
}
}
Cron triggered runs
When a run is triggered by a cron job, its input state will be the final state of the previous run. This allows each subsequent run to know about previous runs. In other words, you can pass information from one run to another even if they happen days apart.
Example scenario: You have a daily sync at 9 AM with a workflow that has
3 steps: (1) fetch patient records, (2) transform data, (3) send to database. On
Monday, the workflow processes records up to ID 1000 and outputs
{ lastProcessedId: 1000 } as its final state. On Tuesday at 9 AM, the cron job
starts again with { lastProcessedId: 1000 } as its input, so it knows to fetch
and process records starting from ID 1001.
The first time the workflow runs, the initial state will simply be an empty
JavaScript object: {}
Overriding cron input
You can always manually run a cron-triggered workflow with:
- Empty input:
{}- starts fresh without previous state. - Custom input: Your own data to test specific scenarios.
- Default input: Uses the same input as the scheduled runs.
If the manual run succeeds, the next scheduled cron run will start with whatever output state your manual run produced.
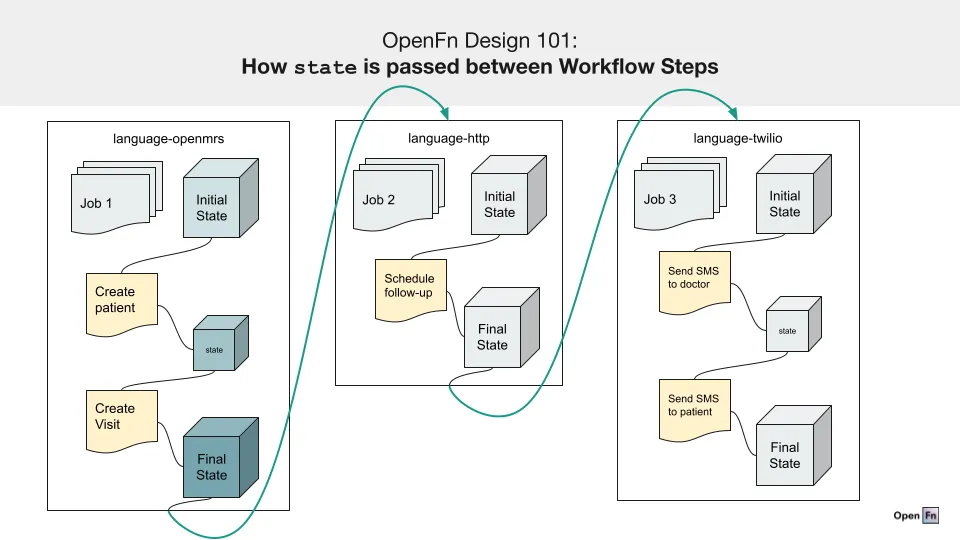
Input & output state for steps
State is also passed between each step in a workflow. The output state of the previous step is used as the input state for the next step.
On success
When a job succeeds, its output state will be whatever is returned by the last operation.
{
data: { patients: [] },
references: [1, 2, 3]
}
On failure
When a step in a workflow fails, the error will be added to an errors object
on state, keyed by the ID of the job that failed.
{
data: { patients: [] },
references: [1, 2, 3],
errors: {
jobId: { /* error details */ }
}
}
See the below diagram for a visual description of how state might be passed between Steps in a Workflow.