What is OpenFn?
OpenFn is the leading Digital Public Good for workflow automation.
It is a platform that's been used by 70+ NGOs and government ministries to automate and integrate critical business processes and information systems.
Connect any app with OpenFn's library of open-source Adaptors (i.e., connectors). From last-mile services to national-level reporting, OpenFn boosts efficiency & effectiveness while enabling secure, stable, scalable interoperability at all levels.
OpenFn can be deployed locally or on the secure cloud-hosted platform. See the Deployment docs for more on deployment options and requirements.
To support implementers, OpenFn has an online community, documentation, and support. Contact partnerships@openfn.org to learn about OpenFn implementation partners and the OpenFn Partner Program.
OpenFn is open source software that makes it easier for governments and NGOs to connect the different technologies they use, automate critical business processes, and scale their interventions. OpenFn enables automation, integration, and data interoperability for the worlds most impactful organizations.
Our products
OpenFn has a suite of products, which are all fully interoperable. This gives our users the freedom to switch between any and all of the OpenFn products.
All OpenFn products, other than the OpenFn v1 iPaaS, are part of the free and
open-source OpenFn Integration Toolkit, which is a Digital Public Good (a
"DPG") recognized in the
DPG Registry and Digital Square's
Global Goods Guidebook.
The core OpenFn products include:
- OpenFn/lightning: our open source data integration & workflow automation platform. This is the "v2" version currently in use.
- OpenFn/platform: the first version of our platform. Replaced by v2 and due to be sunsetted in 2025
- OpenFn/adaptors: source code for adaptors
- OpenFn/kit: CLI, developer tools and Javascript runtimes
- OpenFn/docs: documentation & source for docs.openfn.org
See all products and code at GitHub.com/OpenFn.
OpenFn v2: Lightning ⚡
When you hear "OpenFn", think OpenFn/lightning. v2 is a fully open source workflow automation web application which can be deployed and run anywhere. It is designed for governments and NGOs who want state-of-the-art workflow automation and data integration/interoperability capabilities with fully-fledged user management and auditing capabilities through a managed or entirely self-hosted platform.
Version 2 leverages the same tried-and-trusted core technology as the OpenFn v1 and comes with an improved, visual interface for building integrations.
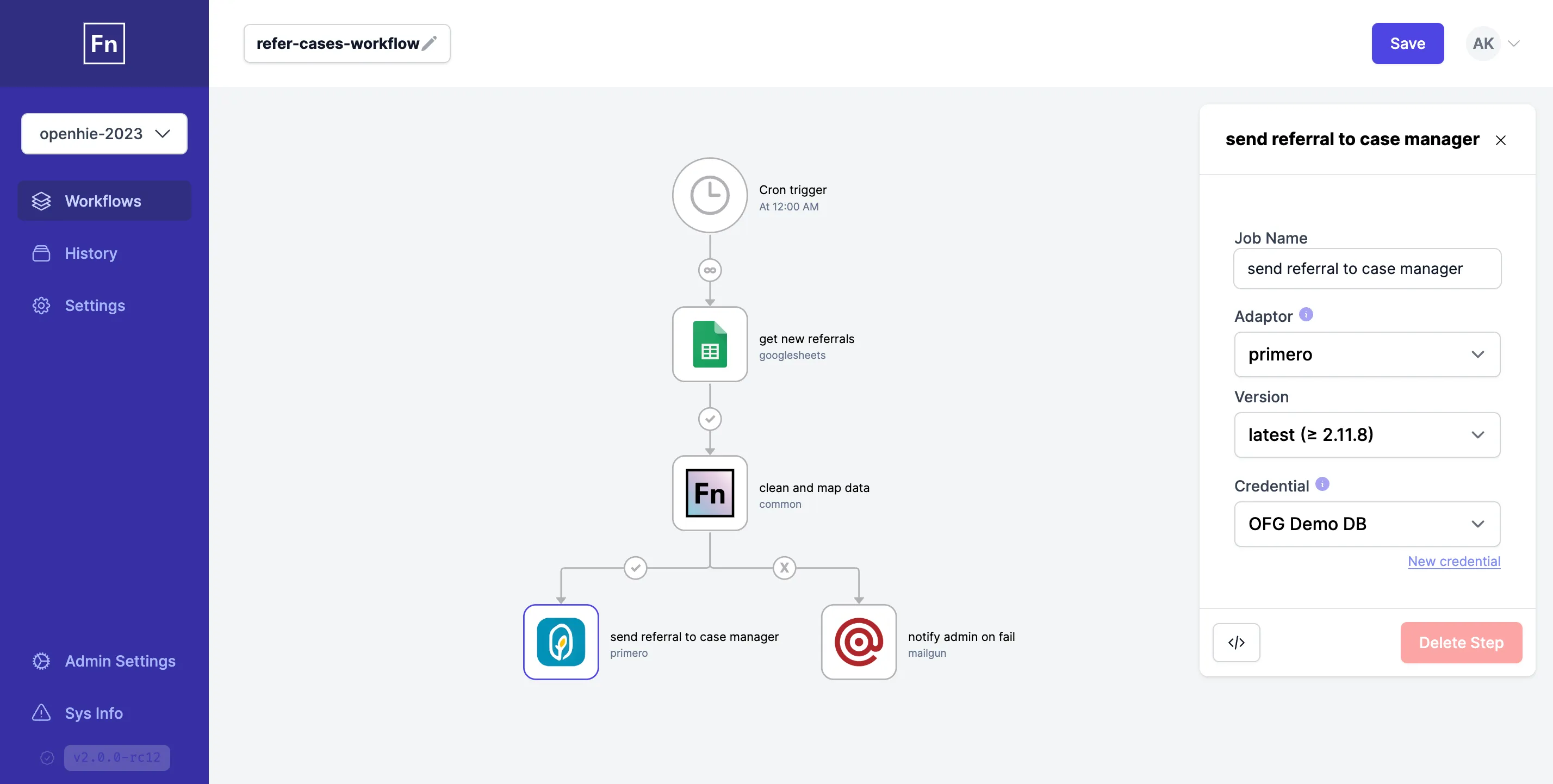
Check out the OpenFn v2 Basics playlist on Youtube to watch videos that will help you get started quickly, or check out the other docs pages on the site.
OpenFn v2 is available to any new users. All organizations currently using the legacy OpenFn v1 platform will be migrated to OpenFn v2 by the end of 2024.
OpenFn v1
OpenFn v1 is the legacy OpenFn integration-platform-as-a-service or "iPaaS" first launched in 2015. OpenFn v1 was open-core with a proprietary web app.
The v1 platform will be sunsetted by 2025 and replaced by the fully open-source OpenFn v2 (see above).
OpenFn developer tooling
OpenFn/kit provides a CLI and set of developer tools for writing & testing workflows, managing OpenFn projects, and developing Adaptors.
You can view the technical documentation and source code for OpenFn's fully open source ("FOSS") integration tools and adaptors in their respective repositories at GitHub.com/OpenFn or see Deploy section for an overview of the FOSS options and additional docs.
Community
To ask questions, report issues, or learn from other OpenFn implementers, check out our Discourse forum at community.openfn.org. Sign up and join the conversation. Usually, that's the quickest way to get help if you've got questions that aren't answered here.
If you have any questions about our products, ask on the Community or email the core team support@openfn.org.
Who is it built by?
The primary steward of OpenFn is Open Function Group, a global team of workflow automation and data integration specialists and core contributors to OpenFn. Learn more about OpenFn's governance here.
The OpenFn Digital Public Good has been built by and for the growing community of NGOs, governments, "tech-for-good" partners, and open-source contributors working on the health and humanitarian interventions in Low- and Middle-income Countries (LMICs).